In the first part of this article, we have discussed about the basics of Image Segmentation, its process, and its use. In this article, we will discuss the type of image segmentation, architectures, loss functions, and some interesting use cases of image segmentation.
Types of Image Segmentation
Image segmentation can be classified into two broad categories:
Semantic segmentation, or image segmentation, gives all pixel values corresponding to a class same pixel values. It is a pixel-level prediction because each pixel in an image is classified according to a class.
2. Instance Segmentation
Instance segmentation is a technique in which all pixels corresponding to a specific object share a unique pixel value. It also includes the identification of boundaries of the objects at the detailed pixel level

Architectures
Fully Convolutional Network
The architecture of CNN has a few Convolutional and pooling layers along with a few fully connected layers at the end. The fully convolutional layer can be thought of as a 1X1 convolution covering the entire region. The advantage of doing this is the size of input needs not to be fixed anymore.
The down-sampling part of the network is called an encoder, and the up-sampling feature is called a decoder. This pattern is seen in many architectures, i.e., reducing the size with the encoder and then up-sampling with the decoder.
U-Net
U-Net builds on the top of FCN (Fully Convolutional Network) from above. It consists of an encoder which down-samples the input image to a feature map and the decoder which up-samples the feature map to input image size using learned de-convolution layers.
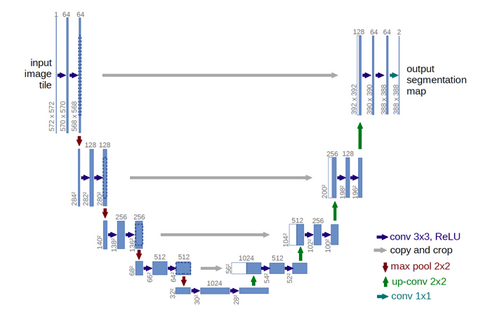
U-Net proposes a modern approach to solve this information loss problem. It proposes to send information to every up-sampling layer in the decoder from the corresponding down-sampling layer in the encode
Mobile NET
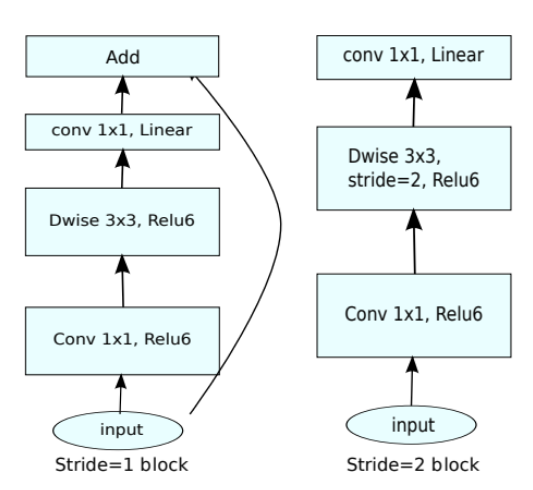
MobileNet is an efficient CNN architecture that is used in real-world applications. MobileNets primarily use depth-wise separable convolutions in place of the standard convolutions used in earlier architectures to build lighter models. MobileNets introduce two new global hyperparameters (width multiplier and resolution multiplier) that allow model developers to trade off latency or accuracy for speed and small size depending on their requirements.
Mask R-CNN
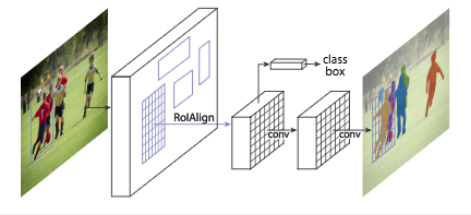
Mask R-CNN extends to solve instance segmentation problems. It realizes this by adding a branch for predicting an object mask in parallel with the existing unit for bounding box recognition. In principle, Mask R-CNN is an intuitive extension of Faster R-CNN, but constructing the mask branch properly is critical for good results.
Back Bones
Backbone is an FPN style deep neural network. It consists of a bottom-up pathway, a top-bottom pathway, and lateral connections. The bottom-up path can be any ConvNet, usually ResNet or VGG, which extracts features from raw images.
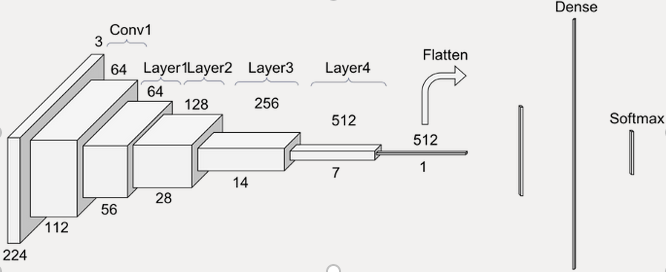
ResNet
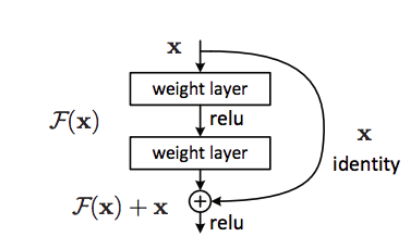
A residual learning framework (ResNets) helps to ease the training of the networks that are substantially deeper than before by eliminating the degradation problem. ResNets are easier to optimize and can have high accuracy at considerable depths.
FPN
Image pyramids (multiple images of multiple scales) are often used to improve the predictions’ results. But computing results using modern deep learning architectures is often an expensive process for both computing and time.
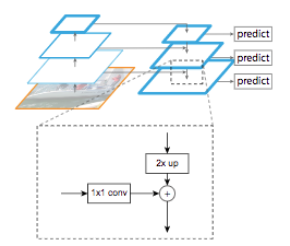
Feature Pyramid Network (FPN) is a feature extractor designed for a pyramid concept with accuracy and speed in mind. It replaces the feature extractor of detectors like Faster R-CNN. It generates multiple feature map layers (multi-scale feature maps) with better quality information than the regular feature pyramid for object detection.
DenseNet
A DenseNet is a convolutional neural network that uses dense connections between layers through Dense Blocks, where we combine all layers (with matching feature-map sizes) directly with each other. It maintains the feed-forward nature; each layer takes additional inputs from all preceding layers and carries on its feature maps to all subsequent layers.


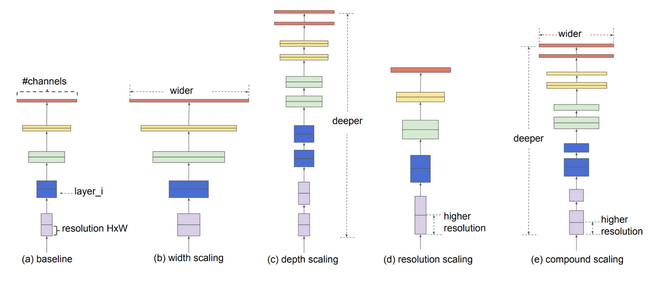
EfficientNet is a convolutional neural architecture and scaling technique that uniformly scales all depth/width/resolution dimensions employing a compound constant. Unlike standard practice that discretionary scales these factors, the EfficientNet scaling technique uniformly scales network breadth, depth, and resolution with a group of fastened scaling coefficients.
Loss Function
The Loss Function is a vital component of Neural Networks. Loss is nothing but a error prediction of Neural Network. And the function used to calculate this loss is called the Loss Function. Basically, the loss is used to compute the gradients. And these gradients in turn are used to update the weights of the Neural Networks. This is how a Neural Nets are trained.
We will be covering the following loss functions, which could be used for most of the image segmentation objectives.
Cross-Entropy Loss: Usually, we use the sigmoid function for binary classification, and the Softmax function is used for multi-class classification to calculate the probability of the sample being a specific class. Regardless of the binary or multi-class classification, the loss function is usually the cross-entropy loss.
Focal Loss: Focal loss function acts as a more effective alternative to Cross-Entropy loss for tackling class imbalance. The loss function is a dynamically sized cross-entropy loss, where the scaling factor declines to zero as confidence in the suitable class increases.
Dice Loss: This loss is obtained by calculating the uniform dice coefficient function. This Loss is the most regularly used loss function in segmentation problems.
Boundary Loss: This variant of boundary loss is applied to projects with unbalanced segmentation. This Loss model is that of a distance metric on space contours and not regions. In this manner, it deals with the obstacle posed by regional losses for extremely imbalanced segmentation tasks.
IoU Balanced loss: The IoU-balanced classification loss aims to increase the gradient of samples with high IoU and decrease the gradient of units with low IoU. In this way, the localization accuracy of machine learning models is increased.
Use Cases
Autonomous Driving Systems: The first step in many autonomous driving systems based on visual inputs is object recognition, object localization, and, in particular, semantic segmentation. These classes could be street, traffic signs, street markings, cars, pedestrians, or dogs in a typical case.

Handwriting Recognition: Handwritten Character Recognition is an area of research for many years. Automation of existing manual systems is a need in most industries as well as government areas. Semantic segmentation helps us to segment a text-based image at various levels of segmentation.

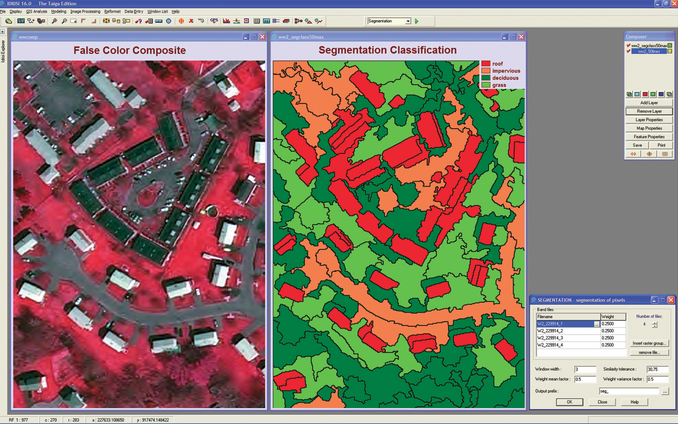
GeoSensing for land usage: Semantic segmentation has a use case for land usage mapping for satellite imagery. Land cover information is essential for various applications, such as monitoring areas of deforestation and urbanization. Semantic segmentation aids us to understand the form of land cover (e.g., areas of land, agriculture, water, etc.) for pixels on a satellite picture. Land cover segmentation can be considered a multi-class semantic segmentation task. Road and building detection is also an essential research topic for traffic management, city planning, and road monitoring.
Medical Imaging: Medical image segmentation is used in various purposes. For example, in imaging field is utilized to locate tumors, analyze anatomical structure, etc. It provides comparable analysis and better contrast resolution. One of the most critical problems in image processing and analysis is segmentation. Medical Image Segmentation Technique (MIST) can be used to extract an anatomical object of interest from a stack of full sequential colors.
Face Segmentation: Semantic segmentation of faces usually involves objects like skin, hair, eyes, nose and mouth. Face segmentation is helpful in many facial applications of computer vision, such as estimation of gender, expression, and age. Notable factors influencing face segmentation data set and model development are variations in lighting conditions, facial expressions, face orientation, occlusion, and image resolution.

Conclusion
This concludes our two-part article about Image Segmentation. Hope it would have given you a deeper explanation of Image Segmentation, its types, architecture, and use cases. Kindly go through our other articles to get to know about other core techniques involved in AI and Machine Learning.