Pathology is a branch of Medical Science that involves the study and diagnosis of a disease. It helps to identify how a particular disease is caused by examining body fluids, such as blood and urine, cells, or tissues to diagnose a disease which helps doctors to examine the severity of a disease.
Objective:
- Analysis of clinical pathology images involve complex image processing steps. One of the common steps is to layer the source images with additional information like annotations and other metadata. Images are typically large and hence this layering can be done only in fragments. Then these layered fragments are stitched together to make it whole.
- The objective of this article is to describe image processing tools for layering and stitching the images together.
Use Case & Benefits:
- The whole-slide images (WSI) made by digitizing microscope slides at diagnostic resolution are very large. We mostly use Tiled image organization, as it is more optimal than a single frame organization.
- Here we use slides of fixed size either rectangle or square. This methodology helps a lot in reducing the memory issues by loading the tiles that are necessary while panning or zooming.
- Stitching helps us in combining the tile images into a large single image. Deep learning is computationally expensive and medical whole-slide images are enormous. Usually, a large portion of a slide isn’t useful, they have the background, shadows, water, smudges, and pen marks.
- By processing the image in a sliding window fashion, we can eliminate the tiles if needed. This can lead to faster, more accurate model training.
Issues related to loading pathology image:
- The major issues while loading the pathology image is the RAM consumption (image, when decompressed, will have to occupy gigabytes of RAM making it hard to run )
- Also, few packages such as slideio are architecture-dependent (does not support ARM architecture).
Handling pathology data using python:
Openslide a C-based library that provides a simple interface for reading whole-slide images, also known as virtual slides, which are high-resolution images used in digital pathology. These images can occupy tens of gigabytes when uncompressed, and so cannot be easily read using standard tools or libraries, which are designed for images that can be comfortably uncompressed into RAM.
Slideio is a python module for the reading of medical images. It allows reading whole slides as well as any region of a slide. Large slides can be effectively scaled to a smaller size. The module uses internal zoom pyramids of images to make the scaling process as fast as possible.
Pyvips is a Python binding for libvips, a low-level library for working with large images. Pyvips can be used to read and manipulate the pyramidal TIFF formats. Pyvips reads the data of the file without loading fully onto the memory, instead, it reads sequentially from the file storage.
Disadvantages of using the above packages:
- Slideio is platform-dependent thus we cannot use this package in ARM machines.
- pyvips (Which allows us to load data from the file system in batch streams instead of loading the whole file in memory at a time) for stitching the images but it was slow and writing the resulting image to the filesystem was very slow compared to the OpenCV.
Splitting images to slides:
We make them into smaller tiles so that we can be able to train them easily, training on a large single image is hard.

Image Restitching:
OpenCV has hconcat and vconcat to join the individual images horizontally and vertically. We can use them to stitch the images. Once the stitching is done we can save the image to the file system using the imwrite function in OpenCV. The input Image resolution was 38474 x 32001, and the tile resolution was 512 x 512. Each row has 62 images and we have 75 columns
Input Image:
- Digital pathology image analysis requires high-quality input images. While there are a large number of images available in The Cancer Genome Atlas (TCGA).
- TCGA offers two types of slides, flash frozen and Formalin-Fixed Paraffin-Embedded (FFPE). Flash-frozen samples are typically produced during surgery in a cryolab to help the surgeon determine if the borders of the tumour are clean( i.e., has the tumour been fully resected). Flash freezing is a fast and “easy” process, but frequently leaves the tissue damaged, giving it a swiss cheese type appearance.
- FFPE slides are the gold standard for diagnostic medicine and are generated by fixing a specimen in formaldehyde and then embedding it in a paraffin wax block for cutting. It has a much nicer appearance, making it more amenable to computational analysis.
- The TCGA has both types of slides available, so care must be taken to obtain the correct cohort and *not* mix cohorts unless specifically part of your experimental design.
Here is the sample FFPE slide whole-slide image (WSI) with 38474 x 32001 resolution and 700 MB size in memory that is loaded in Qui Path Software (which is useful to load large tiff images)
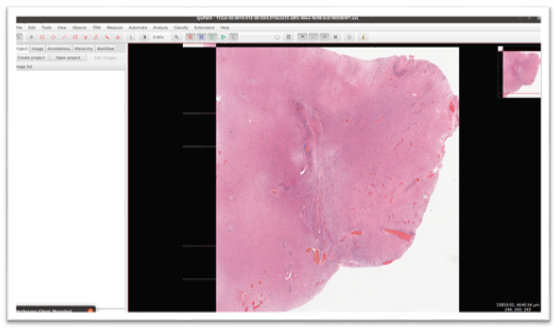
Output Image:
The output image after stitching up all the patches using our algorithm.
Sometimes we want to point out the salient part of an image with saliency maps so if we have a map that should be overlayed on the original image.
We have used OpenCV to generate overlay image here we have used the below-mentioned formula,
Result image = 0.8 * original image + 0.2 * map image

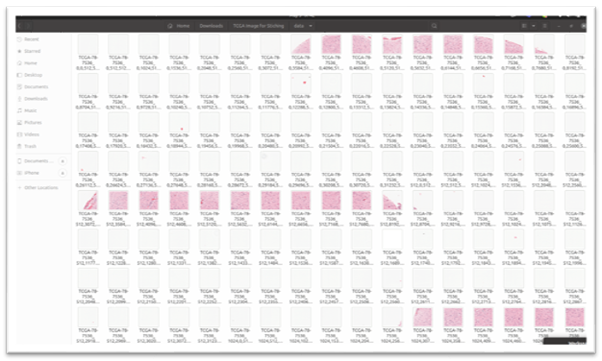
Folder Structure for Data:
Here is the folder structure of patches containing individual tiles extracted from the original WSI image extracted and saved using Pyvips with x, y coordinates.
Simulation of work :
Here is the simulation of stitching up the patches together from left to right.
First, it sorts the images in the patches folder by filename that contains x, y coordinates and then it stitches the patches one by one from left to right
